上手 Trainjob
这一节我们以 Tensorflow 为例,通过 Cloud-ML 平台训练一个简单线性回归模型。通过该例子,我们将介绍:
- 怎样用命令行和 Web 提交训练任务;
- 怎样查看事件和 Log;
- 怎样查看提交的训练任务;
- 怎样删除任务;
示例介绍
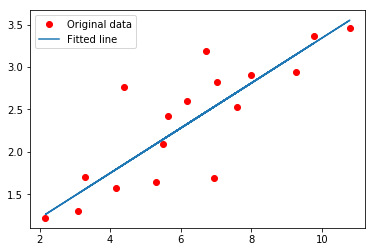
这个例子使用 Tensorflow 实现一个简单的二维线性回归模型。模型使用梯度下降进行优化,学习步长为0.01,迭代1000步,训练后的结果如下图示:
完整代码参考附录1.
代码准备
创建目录结构
创建目录simple_tf_regress(名称可以任意指定),结构如下:
.
|____simple_tf_regress
| |____setup.py # (可选,用于项目代码的构建和分发)
| |____requirements.txt # (可选,用于记录项目可能包含的 Python 依赖)
| |____trainer
| | |______init__.py
| | |____task.py
其中,
setup.py内容如下:import setuptools setuptools.setup(name='cloudml-tutorial-01', version='1.0', packages=['trainer'])其中,
name是压缩包的名字,version是训练代码的版本,packages指定训练代码所依赖的其他第三方函数库。如果指定,Cloud-ML平台会在创建的容器中先进行安装。关于如何编写
setup.py, 详情请参考 Python 文档。requirements.txt保存可用pip安装的依赖,如果指定,Cloud-ML 平台会在执行训练之前先进行安装。更多详情请参考 Pip 文档。
trainer为训练的 Python package;__init__.pyPython package 文件,详情请参考 Python 文档;task.py内容为上面的训练代码;
注意: 这里的trainer是一个 Python Package,里面的 task.py 是我们的训练代码,要执行 task.py 里面的代码,可以执行下面命令,确保代码能在本地正确执行。trainer.task 这个在随后的任务提交中要用到。
python -m trainer.task
如果本地运行没问题,那么我们现在就可以通过命令行提交训练任务了。
使用命令行提交任务
目前Cloud-ML提供两种任务提交方式,分别是命令行提交和通过Web界面提交,分别介绍如下。两者的区别仅在于提交任务的手段不同,后台执行的过程和结果没有任何差异。两种方式,任意选择一种自己喜欢的方式即可。
检查命令行正常工作 使用命令行之前,请先参考第一部分介绍的SDK安装确保命令行成功初始化。
➜ ~ cloudml -v
0.2.11
能正常显示版本信息,则说明命令行正常。
提交任务
cloudml jobs submit -n linear -m trainer.task -u ./simple_tf_regress -d cnbj6-repo.cloud.mi.com/cloud-ml/tensorflow-gpu:1.7.0-xm1.0.0 -c 0.5 -M 100M
上面命令涉及的参数解释如下:
| Required | Argument | Type | Example |
|---|---|---|---|
| Yes | -n --name | string | linear |
| Yes | -m --module_name | string | trainer.task |
| Yes | -u --trainer_uri | string | ./simple_tf_regress |
| No | -c --cpu_limit | int | 0.5 |
| No | -M --memory_limit | string | 100M |
| No | -d --docker_image | string | cnbj6-repo.cloud.mi.com/cloud-ml/tensorflow-gpu:1.7.0-xm1.0.0 |
其中:
-cMd三个参数是可选参数,如果用户不指定,命令行程序会自动用默认填充,但在实际提交给平台的时候仍然是必须的参数;-u --trainer_uri支持训练项目的本地相对路径或绝对路径,同时也支持用户打包上传到 FDS 后的文件链接(主要用于 Web 提交任务);注1: 客户端支持
-u指定本地项目路径,实现逻辑是客户端自动打包上传到 FDScloudml_default_fds_bucket下的user_packages/路径里,上传包名会添加时间信息后缀,使用路径如不存在会尝试创建,因此,为了该功能正常工作,需要用户对配置的cloudml_default_fds_bucket可写, 更多关于cloudml_default_fds_bucket的说明,参考:使用fuse 。注2: 后续章节中可能选取本地路径或 FDS 链接两种支持方式中的其中一种举例,如无特殊情况,不再做重复说明,用户可自行选取适合方式;
- 更多详细的参数帮助信息,请使用
cloudml jobs submit -h查看。
提交之后,Cloud-ML返回下面结果:
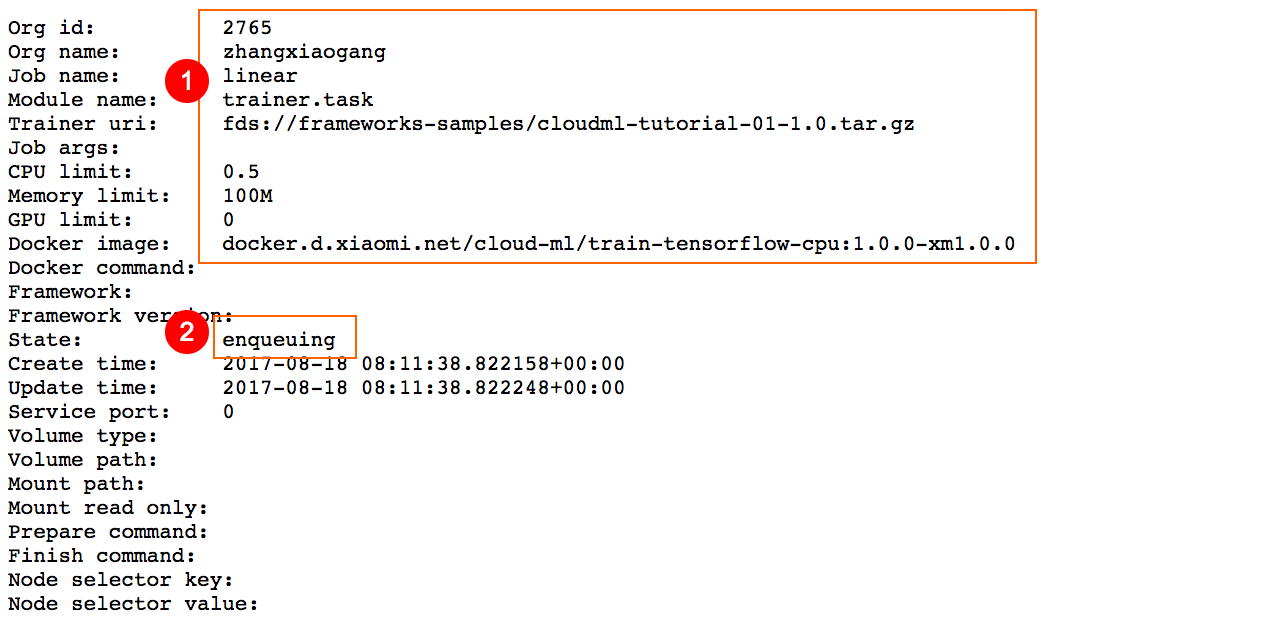 提交后的任务处于
提交后的任务处于enqueuing状态。 Cloud-ML的任务状态变化参考附录2,Trainjob状态图。
查看任务列表
cloudml jobs list
结果如下:
 这时候的状态是
这时候的状态是processing。
查看任务Log
cloudml jobs logs linear
结果如下:
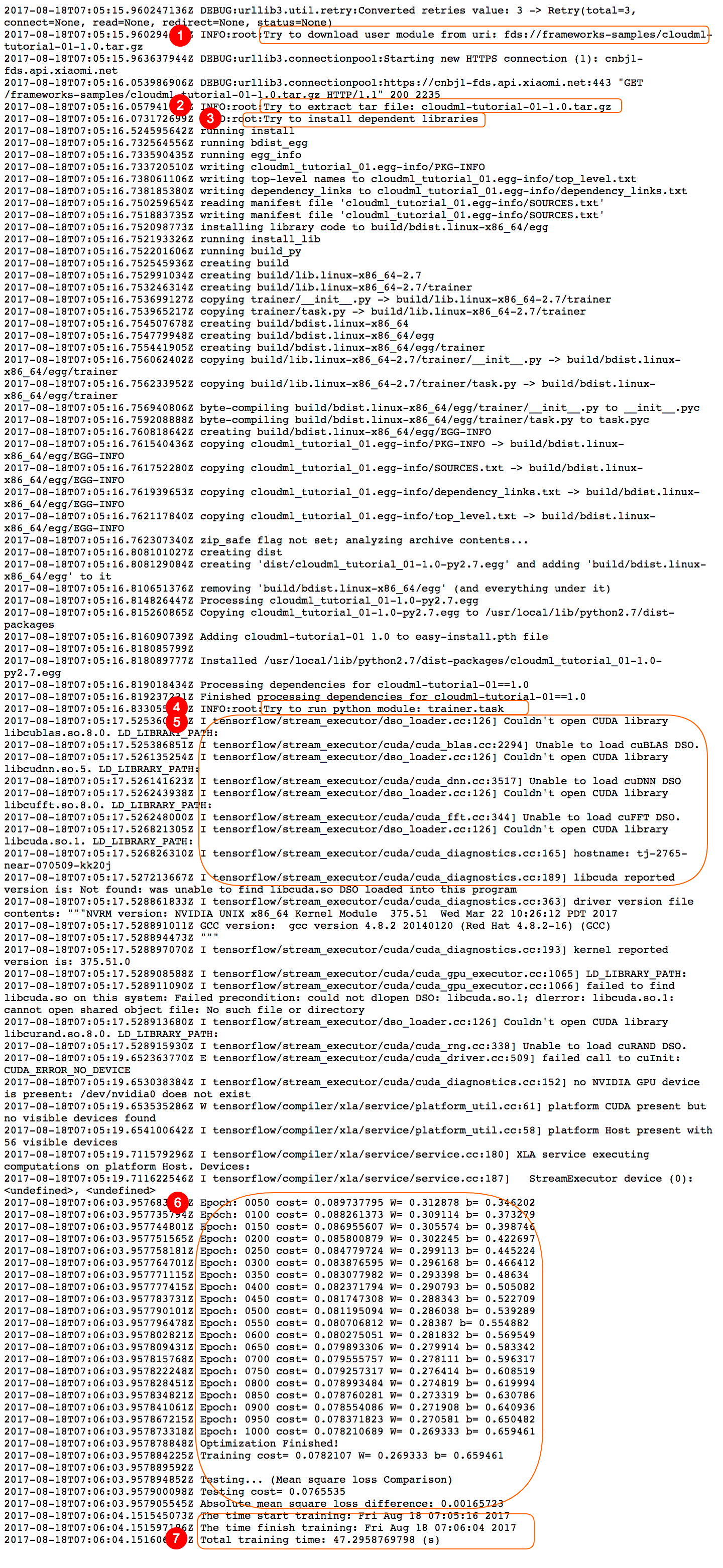
这个Log有些冗长,但是从Log上可以看出Cloud-ML的内部执行过程,简要介绍如下:
首先,容器创建成功后,首先从指定的FDS地址下载代码包;
第二步,解压;
第三步,安装第三方依赖包;
第四步,开始执行代码;
第五步,如果一切正常,我们看到Tensorflow的Log输出;
第六步,用户输出的Log
第七步,是Cloud-ML平台给出一个简要的训练摘要,如训练时间。
cloudml jobs logs 高级选项:

其中:
-f, --follow提供对训练容器日志的跟随查看模式,类似tail命令的-f,实时展示最新日志流;-n LINES, --lines LINES支持整数参数,用来控制返回日志中的最后LINES行,不指定默认返回从训练容器被创建开始的所有日志,通过-n方便用户在大量输出情况下控制输出的内容数量;-f和-n LINES可以组合使用;
有两点需要注意:
- Log的产生在容器成功创建之后,所以有时候查看Log的时候,会看到提示“容器还未创建”,这时候需要等待一小会儿,如果时间过长(比如>5分钟)则很可能容器创建出错,请联系管理员。
- 在任务结束以后,系统会对容器的Log保存一段时间,超过这个时间的容器的Log会被删除。
查看任务事件
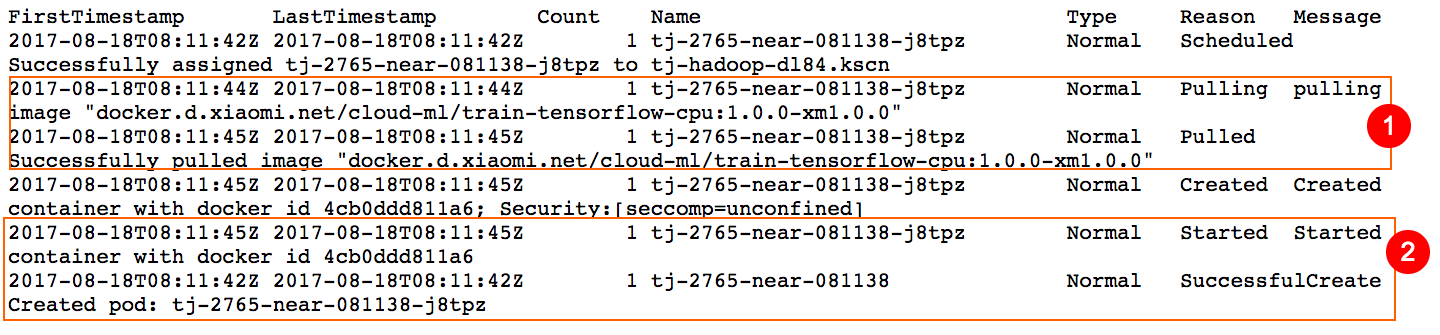
Cloud-ML平台底层依赖Kubernetes对容器进行管理。容器的生命周期的变迁涉及不同的状态,状态的变迁对应不同事件。Cloud-ML提供了接口可以方便用户查看容器的事件。 一般来说,用户并不太关心更底层的操作,除非如上面介绍,当Log查看出问题的时候,可以通过平台提供的事件接口查看更底层的操作。
可以用下面的命令查看任务的事件
cloudml jobs events linear
结果如下:
删除任务
在Cloud-ML中一个org下的任务的名称是不能相同的,那些执行完成的任务,可以使用下面命令删除。可在任务的不同阶段进行删除。
cloudml jobs delete linear
使用Web界面提交任务
首先登录 生态云首页,按照如下步骤进行操作。
与命令行方式不同,Web 页面提交训练任务需要使用项目代码的 FDS 地址,因此我们需要首先打包项目代码并上传 FDS。
打包(方案一,使用 setup.py)
对于准备了 setup.py 的训练项目,进入simple_tf_regress目录,使用下面命令:
python setup.py sdist --format=gztar
完成后,我们会看到下面目录结构:
.
|____simple_tf_regress
| |____cloudml_tutorial_01.egg-info
| | |____dependency_links.txt
| | |____PKG-INFO
| | |____SOURCES.txt
| | |____top_level.txt
| |____dist
| | |____cloudml-tutorial-01-1.0.tar.gz
| |____setup.py
| |____trainer
| | |______init__.py
| | |______init__.pyc
| | |____task.py
其中, ./dist目录下面的内容cloudml-tutorial-01-1.0.tar.gz是我们需要上传的代码包。
打包(方案二,使用 tar)
对于没有准备 setup.py 的训练项目,我们也支持通过 tar 命令直接进行打包。
注1: 如果项目代码中包含了有任何其他 Python 依赖,请添加到顶层目录下的
requirements.txt中;注2: 如果项目代码中包含了有训练数据目录,不建议直接打包,请通过其他方式添加到训练环境中,比如 HDFS、FDS 等;
来到 simple_tf_regress 目录,使用下面命令:
cd ..
tar -czf simple_tf_regress.tar.gz simple_tf_regress
完成后,我们在当前目录下就会看到 simple_tf_regress.tar.gz, 这就是我们需要上传的代码包。
上传代码到 FDS
FDS 可以使用命令行或 Web 界面上传,详情请参考FDS文档。
这里假定已经上传到下面目录:
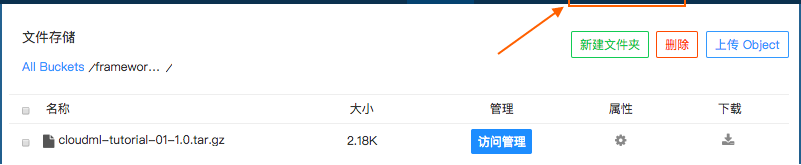
注意: 后面任务提交时指定的 FDS 集群地址需要跟这儿的保持一致,否则,Cloud-ML 将不能正确的下载代码。
创建任务
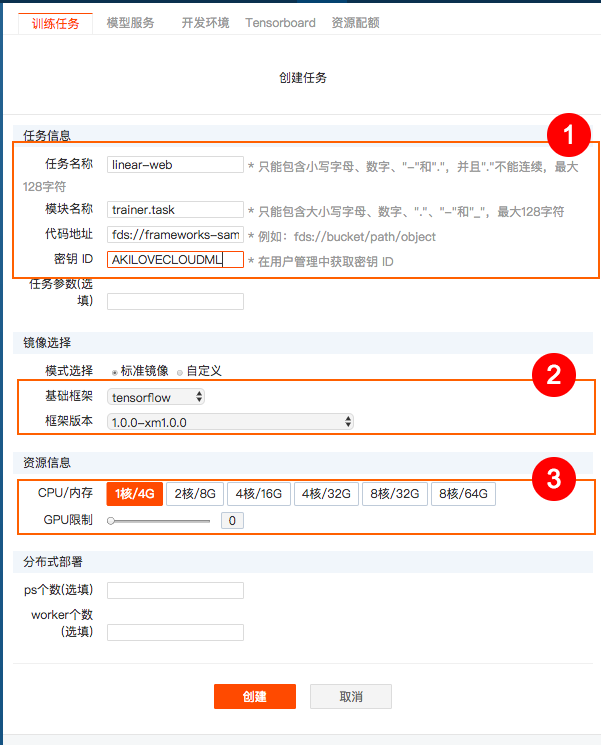
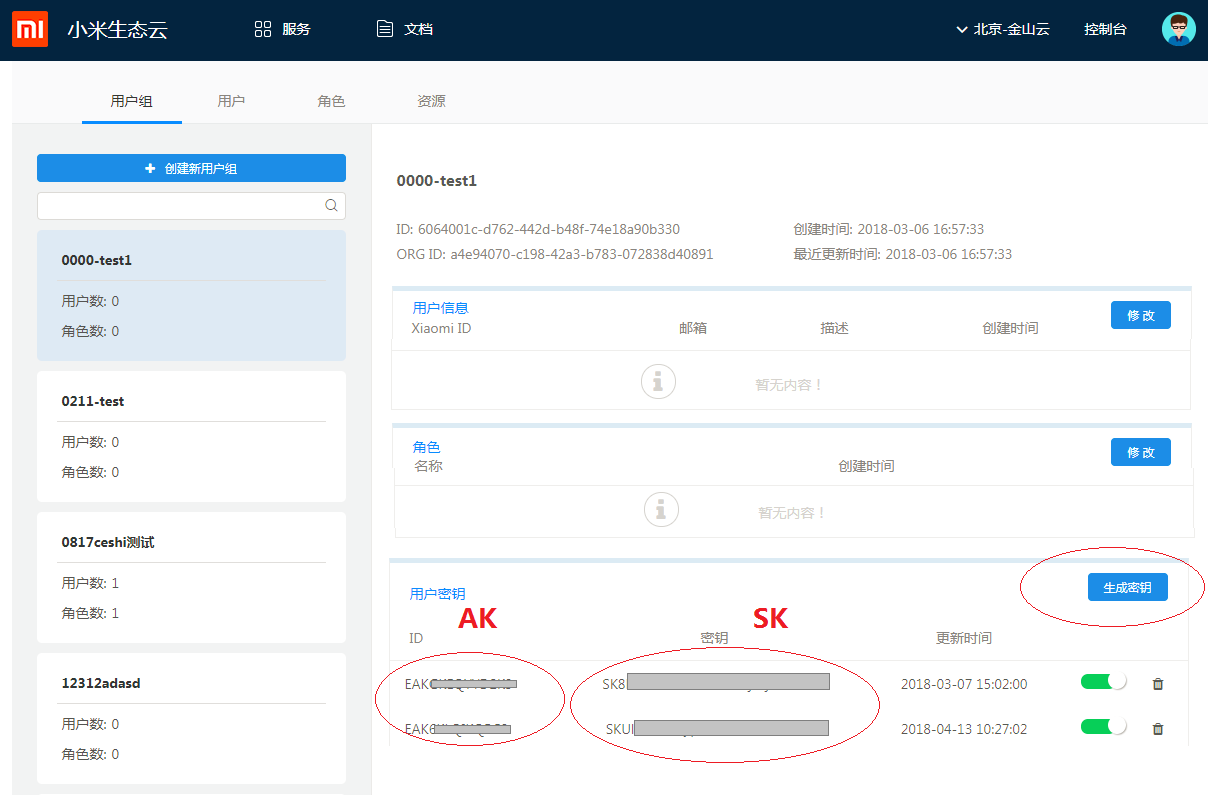
跟命令行不同,这里需要输入一个“秘钥ID”,获取方式请参考附录3,获取"密钥ID"
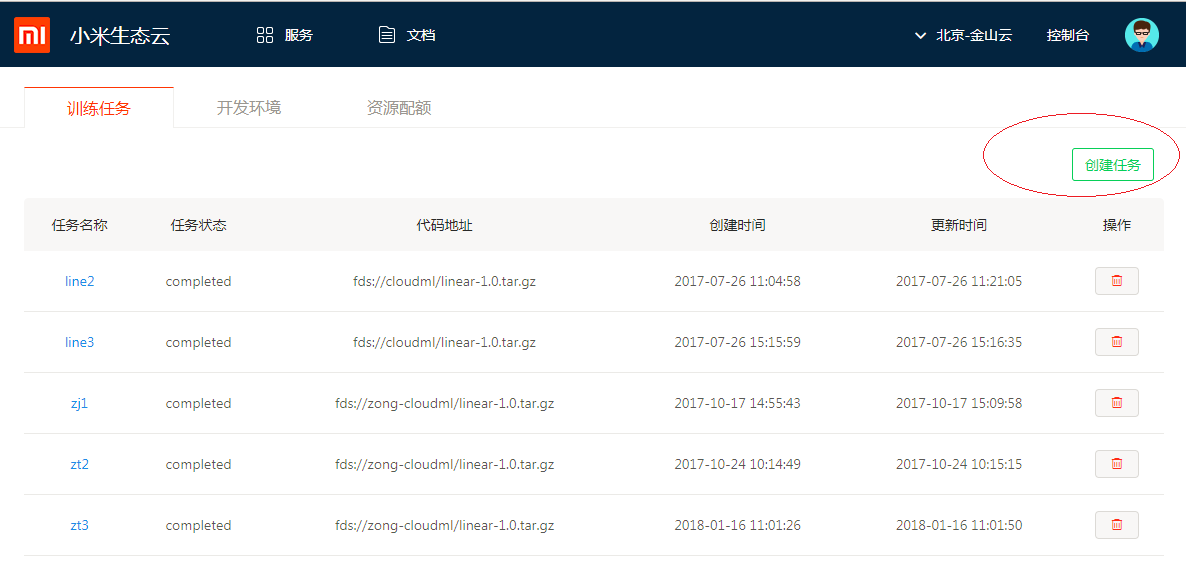
查看任务列表
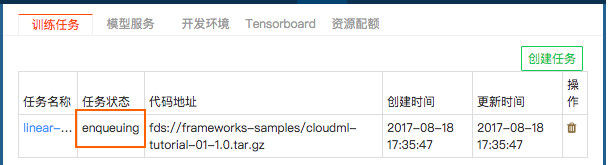
查看任务事件和Log

附录1,示例代码
'''
A linear regression learning algorithm example using TensorFlow library.
Author: Aymeric Damien
Project: https://github.com/aymericdamien/TensorFlow-Examples/
'''
from __future__ import print_function
import tensorflow as tf
import numpy
rng = numpy.random
# Parameters
learning_rate = 0.01
training_epochs = 1000
display_step = 50
# Training Data
train_X = numpy.asarray([3.3,4.4,5.5,6.71,6.93,4.168,9.779,6.182,7.59,2.167,
7.042,10.791,5.313,7.997,5.654,9.27,3.1])
train_Y = numpy.asarray([1.7,2.76,2.09,3.19,1.694,1.573,3.366,2.596,2.53,1.221,
2.827,3.465,1.65,2.904,2.42,2.94,1.3])
n_samples = train_X.shape[0]
# tf Graph Input
X = tf.placeholder("float")
Y = tf.placeholder("float")
# Set model weights
W = tf.Variable(rng.randn(), name="weight")
b = tf.Variable(rng.randn(), name="bias")
# Construct a linear model
pred = tf.add(tf.multiply(X, W), b)
# Mean squared error
cost = tf.reduce_sum(tf.pow(pred-Y, 2))/(2*n_samples)
# Gradient descent
# Note, minimize() knows to modify W and b because Variable objects are trainable=True by default
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
# Initializing the variables
init = tf.global_variables_initializer()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Fit all training data
for epoch in range(training_epochs):
for (x, y) in zip(train_X, train_Y):
sess.run(optimizer, feed_dict={X: x, Y: y})
# Display logs per epoch step
if (epoch+1) % display_step == 0:
c = sess.run(cost, feed_dict={X: train_X, Y:train_Y})
print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(c), \
"W=", sess.run(W), "b=", sess.run(b))
print("Optimization Finished!")
training_cost = sess.run(cost, feed_dict={X: train_X, Y: train_Y})
print("Training cost=", training_cost, "W=", sess.run(W), "b=", sess.run(b), '\n')
# Testing example, as requested (Issue #2)
test_X = numpy.asarray([6.83, 4.668, 8.9, 7.91, 5.7, 8.7, 3.1, 2.1])
test_Y = numpy.asarray([1.84, 2.273, 3.2, 2.831, 2.92, 3.24, 1.35, 1.03])
print("Testing... (Mean square loss Comparison)")
testing_cost = sess.run(
tf.reduce_sum(tf.pow(pred - Y, 2)) / (2 * test_X.shape[0]),
feed_dict={X: test_X, Y: test_Y}) # same function as cost above
print("Testing cost=", testing_cost)
print("Absolute mean square loss difference:", abs(
training_cost - testing_cost))
附录2,Trainjob状态图
Cloud-Ml Trainjob有下面几种状态:

解释如下:
首先,用户提交Trainjob后,Cloud-ML将其置为enqueuing,这个时候,任务处于等待队列中。在Cloud-ML内部有一个“叫号器”,每隔一段时间从队列中将等待的任务提取出来交给执行平台(即Kubernetes集群),目前这个时间间隔设置为10秒钟,因此,从用户的角度上看,提交任务后,马上使用cloudml jobs list看到的任务状态可能有一小段时间一直处于enqueuing;
当任务被成功提交给Kubernetes集群后,Cloud-ML将任务状态置为enqueued。需要说明的是,这个状态仅是表明任务被调度过去了,能否执行,还要看Kubernetes的调度策略,比如当集群资源很紧张的时候,任务将处于Kubernetes的等待队列中,什么时候执行,甚至能否成功执行,要看Kubernetes当时的具体运行情况;
如果任务很顺利地被Kubernetes成功调度,这时候Cloud-ML会将其置为processing,这个时候任务已经开始执行了,这中间就涉及到我们在[组件和流程](./00_trainjob_workflow.md)中描述的很多环节;需要特别说明的是,processing这个状态有可能会不正常的持续很长很长时间,举个例子,比如因为计算节点的问题导致任务不断的被重复调度,这个时候该任务将一直处于processing。对用户来说,如果感觉自己任务的处理时间已经超出了正常的范围,需要及时联系管理员检查任务是否有问题;
如果一切顺利的话,任务会被执行成功,Cloud-ML将其置为completed。完事大吉了吗?不一定。比如,当用户的代码里面有Bug,导致程序(是的,用户自己的程序)异常退出,从Kubernetes集群的角度上看,任务已经完成,容器可以销毁,并愉快的告诉Cloud-ML一切都很好。对用户来说,如果感觉自己的任务比预想的时间要快得多的完成,这时候稳妥的办法是cloudml jobs logs <job_name>看一下Log,一般来说都会有异常信息提示。
总之,成功的执行一次训练任务牵涉很多环节,状态也是变化多端;作为Cloud-ML平台来讲,后面还需要有进一步的完善,力求使任务状态对用户来说清晰明确。
附录3,获取"密钥ID"