GPU使用率监控
简介
Xiaomi Cloud-ML底层使用kubernetes+docker调度资源,GPU分配的粒度是个,不存在GPU共享的情况。当前集群的服务器都是4卡机型,编号从0到3。
GPU使用率每分钟抓取一次,推送到falcon上。
基本概念
Cloud-ML对用户的任务进行了封装,调度的pod以一定的规则命名,用户可以使用我们sdk提供的events功能查看任务Name项,该项展示的就是我们后端调度的虚拟单元的名称。具体规则如下(由于原先命名较短,服务端更新之前,仍将使用旧版的命名方式):
# Train Job, 旧版本
"{}-{}-{}-{}".format("tj", str(org_id)[-4:].lower(), job_name[-4:].lower(), create_time.strftime("%H%M%S"))
# Train Job, 新版本
"{}-{}-{}-{}".format("tj", str(org_id)[-5:].lower(), job_name[-16:].lower(), create_time.strftime("%m%d%H%M%S"))
# Model Service,旧版本
"{}-{}-{}-{}".format("ms", str(org_id)[-4:].lower(), model_name[-4:].lower(), create_time.strftime("%H%M%S"))
# Model Service,新版本
"{}-{}-{}-{}-{}".format("ms", str(org_id)[-5:].lower(), model_name[-16:].lower(), model_version, create_time.strftime("%m%d%H%M%S"))
# Dev Env,旧版本
"{}-{}-{}-{}".format("de", str(org_id)[-4:].lower(), dev_name[-4:].lower(), create_time.strftime("%H%M%S"))
# Dev Env,新版本
"{}-{}-{}-{}".format("de", str(org_id)[-5:].lower(), dev_name[-16:].lower(), create_time.strftime("%m%d%H%M%S"))
使用流程
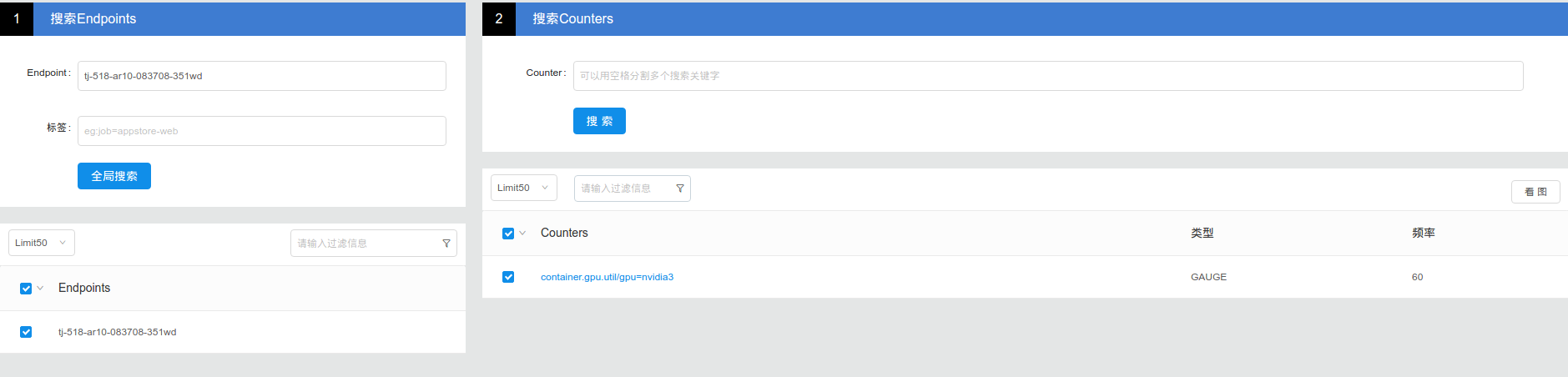
用户可以在创建任务之后,使用上述命名规则拼接endpoint名称,或者使用events功能获取服务端创建的endpoint名(当前服务端仍是旧版命名方式):

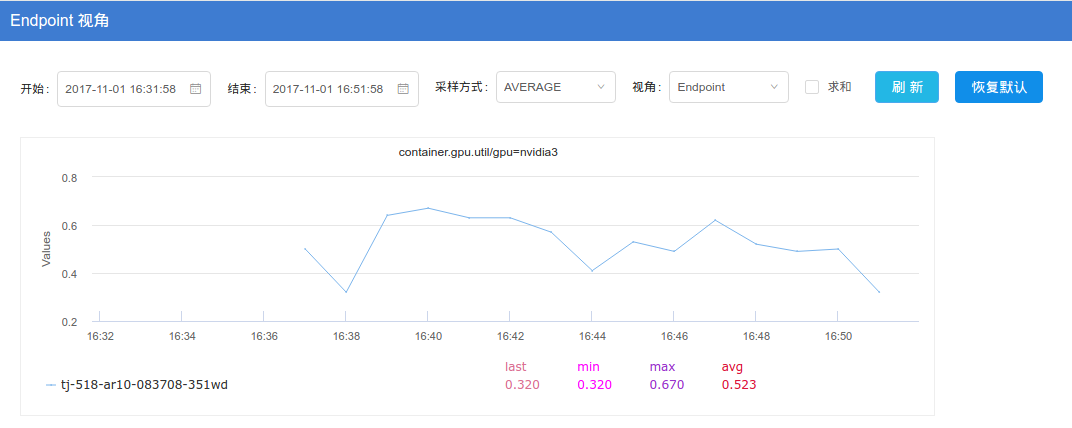
之后在falcon的endpoint项中搜索tj-518-ar10-083708-351wd:
监控的结果: