上手超参调优任务(HpJob)
这一节我们以 tensorflow linear 为例,通过 Cloud-ML 平台训练一个简单线型模型。通过该例子,我们将介绍:
- 怎样用命令行提交训练任务;
- 怎样查看日志;
- 怎样查看提交的超参调优任务;
- 怎样通过Web Ui查看任务结果;
- 怎样删除任务;
示例介绍
这个例子使用tensorflow实现一个简单的线型模型。
完整代码参考附录1.
代码准备
创建目录结构
HpJob的目录结构和注意事项与Trainjob完全相同
代码要求
Hojob的本质是帮助用户挑选表现最优的超参组合值,Cloud-Ml依据什么来判断训练结果的优劣呢?Cloud-Ml平台通过分析每组训练日志中的目标属性值来判断训练结果的优劣,其中训练代码必须按照一定的格式输出特定的目标属性值。目标属性在下面会具体说明,目标属性值的输出格式如下:
cost=0.28 b=12.4 W=0.12
cost=0.18 b=1.6 W=-0.01
其中,
cost指目标属性,以键值对的形式记录在日志文件中,b和W是可选属性,用户也可以指定别的属性,也可以不指定,Cloud-Ml平台在收集目标属性值时可以帮助用户收集用户的其他属性,用户可以先利用#附录1,示例代码进行训练,并在Web Ui中查询训练结果。
注意:
- 目标属性的输出格式必须按照键值对的形式,且前后不能有别的字符也不能有空格,例如:
cost= 0.28和cost=0.28,这些格式Cloud-Ml平台都无法解析,进而导致任务发生错误。 - 用户需在本地测试通过后再提交任务,在本地测试时主要考察这几个点:日志中的目标属性值输出格式是否规范,训练代码能否正确接受外部传递的参数
使用命令行提交任务
目前HpJob只支持命令行提交任务,并且因为超参的设置略微复杂,命令中只支持利用Json文件提交相关参数,介绍如下。
检查命令行正常工作以及版本是否支持Hpjob
cloudml -V
提交任务
cloudml hp submit -f filename.json
注意:
- 用户可以利用附录中的配置来熟悉HpJob任务的命令行提交,不用改动任何参数。
上面的Json文件中涉及如下参数(键值对):
| Required | Argument | Type | Example |
|---|---|---|---|
| Yes | hp_name | string | "hp_name": "random-example" |
| Yes | module_name | string | "module": "trainer.task" |
| Yes | trainer_url | string | "trainer_url": "fds://bucket/tensorflow_linear.tar.gz" |
| Yes | optimization_type | string | "optimization_type": "minimize" |
| Yes | objectivevalue_name | string | "objectivevalue_name": "cost" |
| Yes | optimization_goal | double | "optimization_goal": 0.1 |
| Yes | parameter_configs | array | 单独解释 |
| No | metrics_names | array | "metrics_names": ["W"] |
| No | suggestion_algorithm | string | "suggestion_algorithm": "random" |
| No | request_number | int | "request_number": 3 |
上面parameter_configs是数组类型,数组中每个元素涉及如下参数(键值对):
| Required | Argument | Type | Example |
|---|---|---|---|
| Yes | name | string | "name": "--lr" |
| Yes | parametertype | string | "parametertype": "double" |
| Yes | feasible | dict | {"min":"0.01","max": "0.03"} |
其中:
- 设为
Yes的参数用户必须指定,如果不指定,命令行会立即返回,平台也会返回错误; hp_name,module_name和trainer_url参数与Trainjob要求相同;optimization_type参数是指目标属性的取值方向,目前支持:maximize,minimize;objectivevalue_name参数就是上面提到的目标属性,Cloud-ml平台根据用户设置的目标属性参数来解析日志并存储目标属性值;parameter_configs参数指定了需要调优的超参名,超参类型和取值范围,其中name指超参名,格式是--+ 超参名,parametertype是参数类型,目前Cloud-Ml平台支持int,double和categorical类型,feasible指取值范围,目前int和double类型对应的feasible参数格式为{"min": "2","max": "7"}, 而categorical类型对应的格式则为{"list": ["sgd","adm","ftrl"]};optimization_goal,Cloud-Ml平台会一直根据用户设置的参数范围生成实例trial,并解析实例的日志输出,当Cloud-Ml平台解析出日志中的目标属性值达到了参数设置的值,就不再生成实例trial,并将收集到的所有数据通过Web Ui呈现出来,需要注意的是这个参数的类型必须为整数或者浮点数,目前不支持别的数据类型;metrics_names参数用来设置同目标属性一同输出的属性,用户如果想得到除目标属性之外的属性值,就需要在metrics_names参数中指定,并且在训练代码中也需要将属性以上面提到的格式输出,这个参数是数组类型,用户可以指定多个属性名,本例中用户就可以指定b或W,也可以将两个属性都添加到metrics_names参数中;suggestion_algorithm参数设置了平台选取参数的算法,目前Cloud-Ml支持random和grid算法;request_number参数设置指定并行调优的trial数,Cloud-Ml平台将每次生成用户指定个数的trial数;
注意:
request_number属性不是指总共的trial数,而是并行的trail数,因此用户在设置这个参数时应该考虑自己的quota,因为实际消耗的quota数是resource*request_number,例如设置cpu_limit=2,request_number=3,则实际需要6个cpu;- 目前支持HpJob的镜像有两个:
cr.d.xiaomi.net/cloud-ml/tensorflow:1.8.0-xm1.0.0-hpjob和cr.d.xiaomi.net/cloud-ml/mxnet:1.1.0-xm1.0.0-hpjob - 这里附录2,HpJob配置给出了上面示例的配置,用户可以参考。
提交之后,Cloud-Ml返回下面结果:
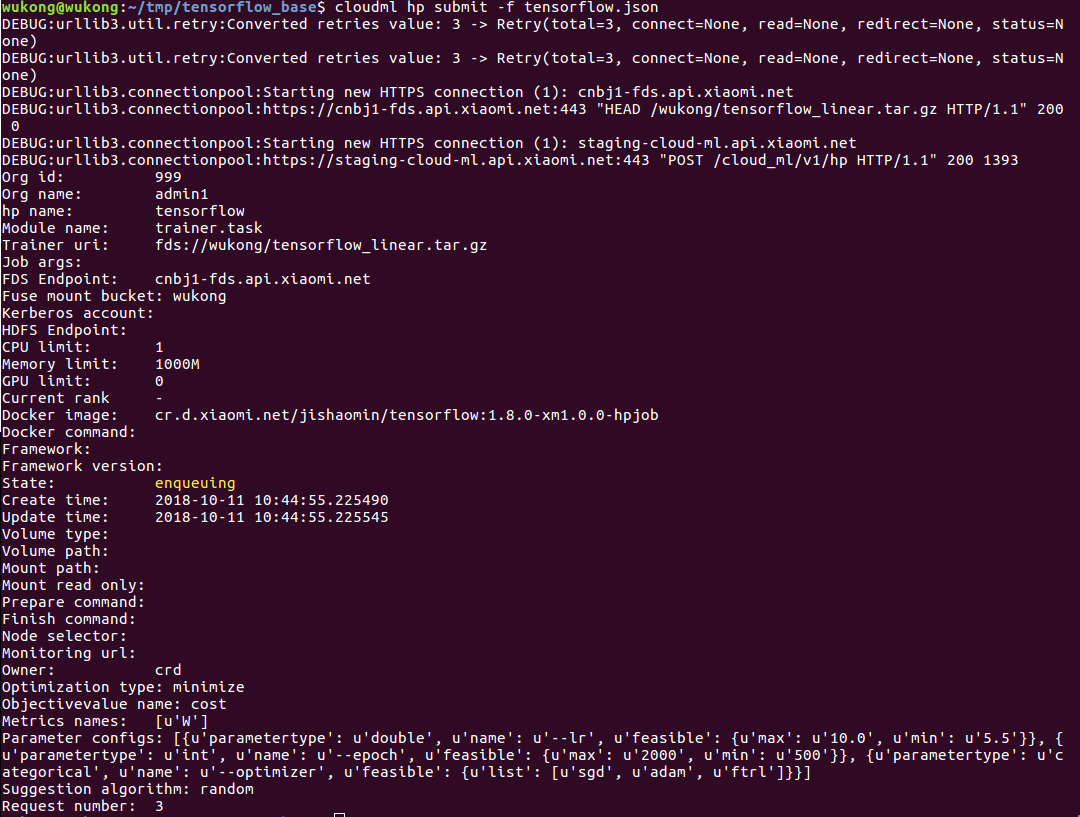 提交后的任务处于
提交后的任务处于enqueuing状态。Cloud-Ml的任务状态变化参考hpjob状态图。
{kind=link}
查看任务列表
cloudml hp list
查看所有的trial
cloudml hp trials tensorflow
结果如下:

一个trial就是特定超参组合值的示例
查看特定trial的log
cloudml hp logs tensorflow -ti f95266e75d0f1700-9wtqx
log指令的高级选项和trainjob查看日志相同
{kind=link}
查看任务描述
cloudml hp describe tensorflow
结果如下:
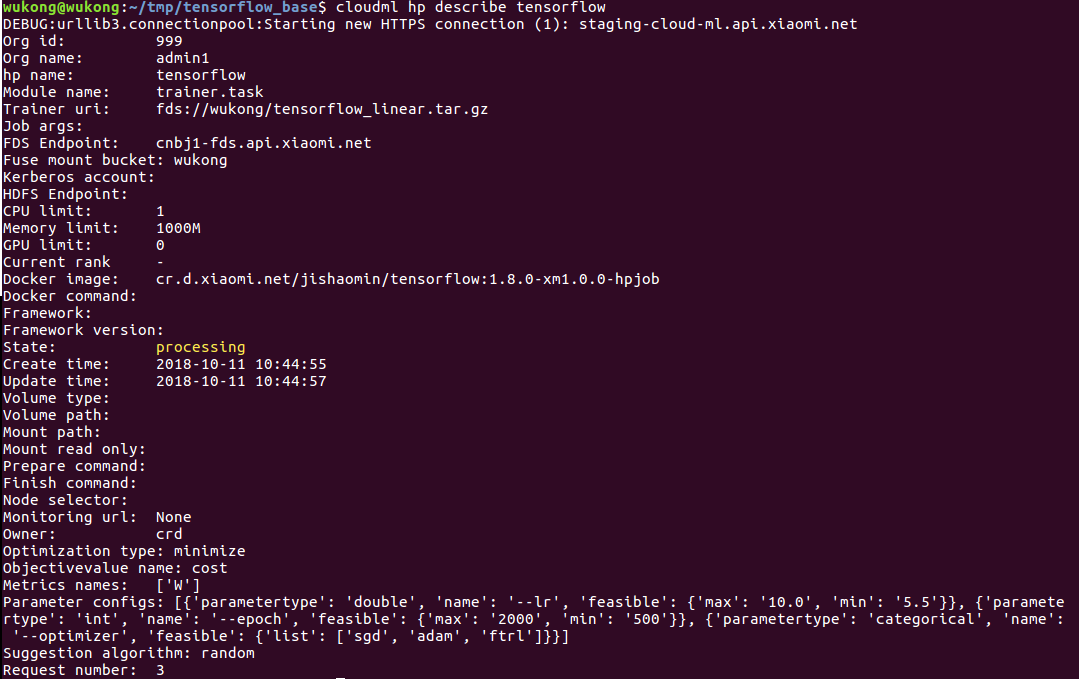 通过描述可以知道任务的执行进度
通过描述可以知道任务的执行进度
查看任务反馈
cloudml hp metrics tensorflow
结果如下:

删除任务
cloudml hp delete tensorflow
附录1,示例代码
'''
A linear regression learning algorithm example using TensorFlow library.
Author: Aymeric Damien
Project: https://github.com/aymericdamien/TensorFlow-Examples/
'''
from __future__ import print_function
import tensorflow as tf
import numpy
import argparse
import sys
import logging
import time
logging.basicConfig(level=logging.DEBUG)
rng = numpy.random
def main():
parse=argparse.ArgumentParser(description="train linear")
parse.add_argument('--lr', dest='lr', default=10, help='learning rate', type=float)
parse.add_argument('--optimizer', dest='optimizer', default='adm', help='optimizers')
parse.add_argument('--epoch', dest='epoch', default=1000, help='training_epochs', type=int)
parse.add_argument('--step', dest='step', default=50, help='dissplay_step', type=int)
args = parse.parse_args()
# Parameters
learning_rate = args.lr
training_epochs = args.epoch
opt = args.optimizer
display_step = args.step
print("lr:{}, epoch:{}, optimizer:{}, step:{}".format(learning_rate,training_epochs,opt,display_step))
# Training Data
train_X = numpy.asarray([3.3,4.4,5.5,6.71,6.93,4.168,9.779,6.182,7.59,2.167,
7.042,10.791,5.313,7.997,5.654,9.27,3.1])
train_Y = numpy.asarray([1.7,2.76,2.09,3.19,1.694,1.573,3.366,2.596,2.53,1.221,
2.827,3.465,1.65,2.904,2.42,2.94,1.3])
n_samples = train_X.shape[0]
# tf Graph Input
X = tf.placeholder("float")
Y = tf.placeholder("float")
# Set model weights
W = tf.Variable(rng.randn(), name="weight")
b = tf.Variable(rng.randn(), name="bias")
# Construct a linear model
pred = tf.add(tf.multiply(X, W), b)
# Mean squared error
cost = tf.reduce_sum(tf.pow(pred-Y, 2))/(2*n_samples)
# Gradient descent
# Note, minimize() knows to modify W and b because Variable objects are trainable=True by default
if opt == 'adm':
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
elif opt == 'sgd':
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
else:
optimizer = tf.train.FtrlOptimizer(learning_rate).minimize(cost)
# Initializing the variables
init = tf.global_variables_initializer()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Fit all training data
for epoch in range(training_epochs):
for (x, y) in zip(train_X, train_Y):
sess.run(optimizer, feed_dict={X: x, Y: y})
# Display logs per epoch step
if (epoch+1) % display_step == 0:
c = sess.run(cost, feed_dict={X: train_X, Y:train_Y})
print("Epoch: {}, cost={:.2f} , W={:.2f} , b={:.2f}".format(epoch+1,c,sess.run(W),sess.run(b)))
print("Optimization Finished!")
training_cost = sess.run(cost, feed_dict={X: train_X, Y: train_Y})
# Testing example, as requested (Issue #2)
test_X = numpy.asarray([6.83, 4.668, 8.9, 7.91, 5.7, 8.7, 3.1, 2.1])
test_Y = numpy.asarray([1.84, 2.273, 3.2, 2.831, 2.92, 3.24, 1.35, 1.03])
print("Testing... (Mean square loss Comparison)")
testing_cost = sess.run(
tf.reduce_sum(tf.pow(pred - Y, 2)) / (2 * test_X.shape[0]),
feed_dict={X: test_X, Y: test_Y}) # same function as cost above
#print("Testing cost=", testing_cost)
print("Absolute mean square loss difference:", abs(
training_cost - testing_cost))
if __name__ == '__main__':
main()
附录2,HpJob配置
{
"hp_name": "tensorflow",
"module_name": "trainer.task",
"trainer_uri": "fds://wukong/tensorflow_linear.tar.gz",
"cpu_limit": "1",
"memory_limit": "1000M",
"docker_image": "cr.d.xiaomi.net/jishaomin/tensorflow:1.8.0-xm1.0.0-hpjob",
"optimization_type": "minimize",
"objectivevalue_name": "cost",
"optimization_goal": 0.01,
"metrics_names": ["W"],
"parameter_configs": [
{
"name": "--lr",
"parametertype": "double",
"feasible":
{
"min": "0.1",
"max": "0.2"
}
},
{
"name": "--epoch",
"parametertype": "int",
"feasible":
{
"min": "500",
"max": "2000"
}
},
{
"name": "--optimizer",
"parametertype": "categorical",
"feasible":
{
"list":[
"sgd",
"adam",
"ftrl"
]
}
}
],
"suggestion_algorithm": "random",
"request_number": 3,
"fds_endpoint": "cnbj1-fds.api.xiaomi.net",
"fds_bucket": "wukong"
}